A Constitution for the AI: How I trust my AI's work I never read?


Some time back, I shipped something that made me conscious. I was building a pipeline that generates intelligence reports with AI. Not drafts, not suggestions for a human to polish. A finished report going out at scale with no human in the loop. The whole point of the system was that nobody reads the output before it leaves.
Which left a question that kept running in the back of my mind: how do I trust the work I will never see?
The problem
The Situation: Things were to be delivered to the client. This made me more skeptical on reading what it generates. I did for the first few reports, but then it started to become hard. I can't read every output now and that defeats the purpose of introducing AI to improve efficiency in work. If a human has to verify everything, I haven't built an autonomous system. Rather, I've built a very expensive draft generator.
The Dilemma: But I also can't just let it go. I've seen what unverified AI output looks like at scale. It's confident, fluent and beautifully wrong in ways that are invisible until a client points them out. So I was stuck between two bad options: verify everything and lose the leverage or verify nothing and lose the trust.
The third option
After having this problem in the back of my mind for 2 weeks, I came to a jugaad (Indian way of saying 'a wayout'). The way out was not to check the output harder. It was to constrain how the output gets made. I wrote a setup for the system that lets the LLM bring its full power, but stay in bounds. Three layers - PLG :
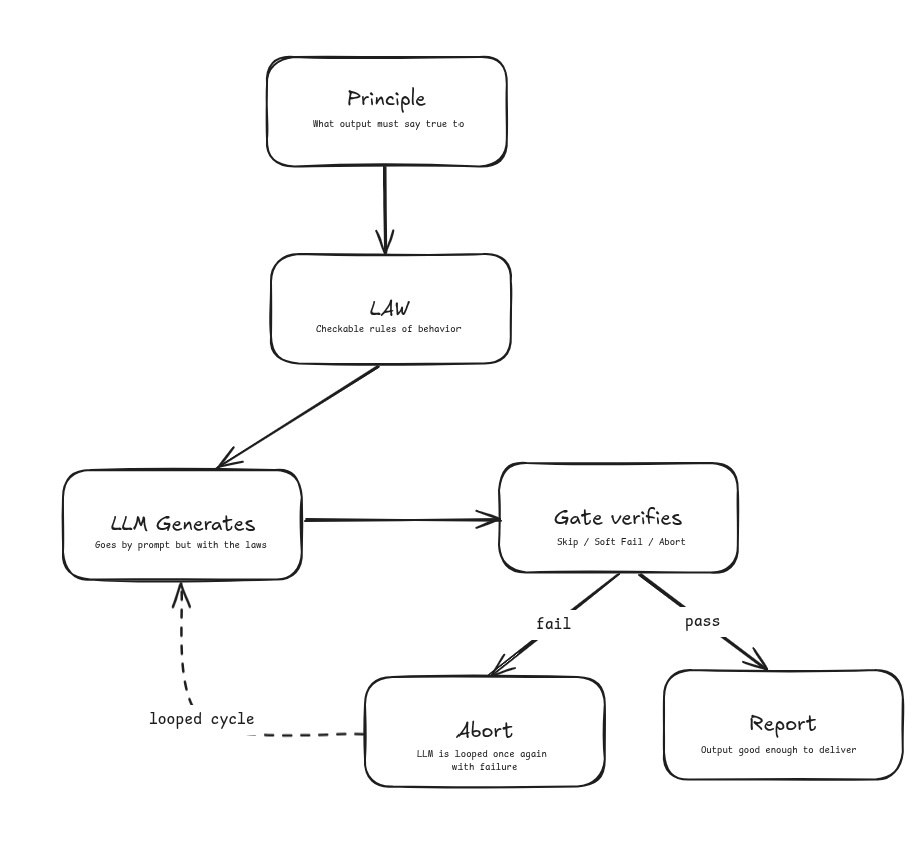
Principles.
The non-negotiables my content must always follow.
These don't tell the AI what to write. They define what the output must always remain true to, regardless of topic. Things like:
- Never present inference as fact.
- Never merge entities without explicit confirmation.
- Every claim must trace back to a source.
Principles establish the values of the system.
Laws.
Rules derived from the principles that direct the narrative.
You may think of it as if principles are values, laws are behavior. For example, if a principle says claims must trace to sources. Then a law says: every named entity in the report must appear in the input data, verbatim. Laws are checkable and that was the whole point.
Gates.
The verification layer.
Gates don't trust the generation step, they are like evaluators. They independently check that the laws were followed before anything ships. If a gate fails, the output doesn't go out. No exceptions, no "it's probably fine." Each gate was defined with a priority flag as skip/soft fail/abort - to show how severe that gate is. For example: one of the gates would check if every claim has a source?
Then I created a readme file which explained all this for generating that report and called it constitution.md. Principles are the values. Laws operationalise them. Gates enforce them. Power gets to move freely inside the structure, and the structure is what makes the power safe to use.
What changed
When I was building it, my objective was that the report should point out to me as a trace on what's wrong in it. With these changes, the output quality landed at the level I would have reached on my third manual verification pass. Not my first read, where I catch the obvious stuff. The third, where I'm catching the subtle errors that only show up once the obvious ones are gone.
One report covered two things with nearly identical numbers, the kind of pair any reader (and any model) would happily treat as one. An earlier version of the pipeline had made exactly this mistake, and it was caught in a manual review. This time, the entity gate flagged that one of the merged stuff never appeared verbatim in the input data, skipped it from the output and rechecked the report. I only found out when I checked the logs. That's the difference: the same error, but the system caught it this time.
Manual review quality depends on my attention, my fatigue, my familiarity with the domain. Gates don't get tired.
The reframe
I started this thinking the question was "how do I verify AI output?" That was the wrong question. Verification scales with volume, and volume always wins.
The better question: how do I make the system worthy of trust before it produces anything? That's what a constitution does. Later I also came across Anthropic's constitutional AI which helped me improve this setup more.
Verification scales linearly with volume. As volume grows, verification eventually loses. Governance scales with the system. The more outputs you generate, the more valuable the guardrails become. That realization changed how I think about that autonomous AI system.
If you're putting AI-generated work in front of customers without a human in the loop, you don't have a verification problem. You have a governance problem. You don't build trust by reading every decision the system makes. You build trust by creating a structure that makes certain failures difficult and certain checks unavoidable. So, probably prompting is just not enough to steer forward. What's your thought?



